Now that all of these CADP archives have been integrated – even if, as been said, much verification work still needs to be done – BiblIndex is building a systematic program for processing the missing works, adopting Biblia Patristica ’s goal of exhaustiveness¸ starting with the 4th and 5th centuries. The first project, which started in August 2017, concerns the works of Augustine, in great demand by internet users. BiblIndex specific guidelines have been drafted5, largely compatible with those of CADP.
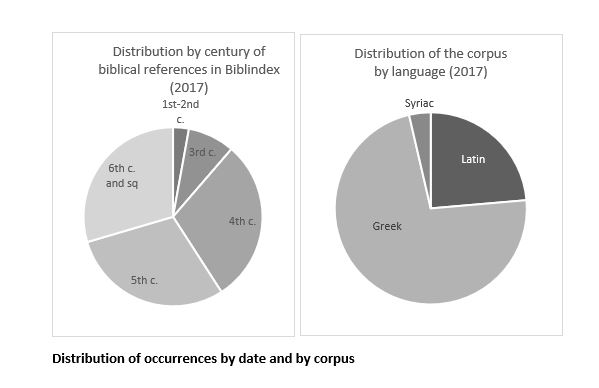
A special effort is planned to integrate the huge field of Eastern Christianity, and first of all Syriac, hitherto unexplored for biblical quotations. Syriac texts’ relationship with the Bible is indeed very interesting because of the linguistic proximity between Hebrew and Syriac. Listing their quotations will enable significant progress to identify or reconstitute the origin of the versions: regarding the Old Testament, the Jewish targums and the New Testament, on the one hand, the Diatessaron, and on the other hand, the Old Syriac – Curetonian or Sinaitic – or finally the Peshitta of the 4th century, which can be compared to the Latin Vulgate. The ten volumes of translation from Syriac in the Sources Chrétiennes series, with their biblical indexes, constitute a starting point, to be broadened, especially with Ephrem’s work published in the Corpus Scriptorum Christianorum Orientalium. The Syriac sources after the 5th century also play a very important role as evidence of Greek works, sometimes lost in their original language (e.g. Severus of Antioch and Theodore of Mopsuestia) 6.
External resources will be added in the process of being analysed, e.g. the quotations found in Bernard of Clairvaux’ works (around 35,000 references); a partnership is being considered with the Faculty of Theology of the Aristotle University of Thessaloniki7: it has developed, thanks to a large team having worked for more than 30 years under the direction of professors S. Sakkos and P. Koutlemanis, a scriptural index, now available in digital form, of approximately 350,000 references, covering the whole of Migne's Greek Patrology; its current manager, Pr. Athanasios Paparnakis, has agreed to make it accessible via BiblIndex8. Another partnership is being intended with the PAVONe project (Platform of the Arabic Versions of the New Testament) of the University of Balamand (Lebanon), which lists not only all the Arabic manuscripts of the New Testament, but also the citations of the New Testament found in lectionaries and other Christian and Muslim literature of the first millennium. In addition, the scriptural indexes of the Sources Chrétiennes series not yet taken into account by the CADP will be added, initially the recent volumes whose indexes will only require a technical revision. In the longer term, links to other databases will be considered, opening up to other cultural and religious areas: Judaism9, Samaritan texts, and Islam.
The architecture is fully modelled, and much of the data is already ready for import. Making them available online as quickly as possible and then being able to easily add new data are priority objectives. Unfortunately, for years, the weakness of the technical means made available to the project, due to insufficient funding, has slowed down the IT development. Various searches for external funding are in progress.